
Повертаючись до суті, прорив AIGC в унікальності є поєднанням трьох факторів:
1. GPT є копією нейронів людини
GPT AI в особі NLP – це алгоритм комп’ютерної нейронної мережі, суть якого полягає в моделюванні нейронних мереж у корі головного мозку людини.
Обробка та інтелектуальна уява мови, музики, зображень і навіть смакової інформації — усе це функції, накопичені людиною
мозок як «білковий комп’ютер» протягом тривалої еволюції.
Тому GPT, природно, є найбільш придатною імітацією для обробки подібної інформації, тобто неструктурованої мови, музики та зображень.
Механізмом його обробки є не розуміння значення, а скоріше процес уточнення, ідентифікації та асоціювання.Це дуже
парадоксальна річ.
Ранні алгоритми семантичного розпізнавання мовлення по суті створювали граматичну модель і базу даних мовлення, а потім відображали мовлення в лексиці,
потім розмістив словниковий запас до граматичної бази даних, щоб зрозуміти значення словникового запасу, і, нарешті, отримав результати розпізнавання.
Ефективність розпізнавання цього розпізнавання синтаксису на основі «логічного механізму» коливалася близько 70%, як, наприклад, розпізнавання ViaVoice
алгоритм, представлений IBM у 1990-х роках.
AIGC не про таку гру.Його суть полягає не в тому, щоб піклуватися про граматику, а скоріше у створенні алгоритму нейронної мережі, який дозволяє
комп’ютер для підрахунку імовірнісних зв’язків між різними словами, які є нейронними, а не семантичними зв’язками.
Подібно до вивчення рідної мови в дитинстві, ми вивчали її природним шляхом, а не вивчали «підмет, присудок, об’єкт, дієслово, доповнення»,
а потім розуміння абзацу.
Це модель мислення ШІ, яка є розпізнаванням, а не розумінням.
Це також підривне значення ШІ для всіх класичних моделей механізмів – комп’ютерам не потрібно розуміти це питання на логічному рівні,
а скоріше визначити та розпізнати кореляцію між внутрішньою інформацією, а потім знати її.
Наприклад, стан потоку електроенергії та прогнозування електромереж базуються на класичному моделюванні електромережі, де математична модель
механізм встановлюється, а потім об’єднується за допомогою матричного алгоритму.У майбутньому це може не знадобитися.ШІ безпосередньо визначить і передбачить a
певний модальний шаблон на основі статусу кожного вузла.
Чим більше вузлів, тим менш популярним є класичний матричний алгоритм, тому що складність алгоритму зростає із збільшенням кількості
вузлів і геометрична прогресія зростає.Однак штучний інтелект віддає перевагу дуже великому масштабу паралельності вузлів, оскільки штучний інтелект добре ідентифікує та
прогнозування найбільш ймовірних режимів мережі.
Будь то наступний прогноз Go (AlphaGO може передбачити наступні десятки кроків із незліченними можливостями для кожного кроку) чи модальний прогноз
складних погодних систем точність штучного інтелекту набагато вища, ніж механічних моделей.
Причина, чому енергомережа наразі не вимагає штучного інтелекту, полягає в тому, що кількість вузлів у мережах 220 кВ і вище, якими керують провінційні
диспетчеризація невелика, і встановлено багато умов для лінеаризації та розрідження матриці, що значно зменшує обчислювальну складність
модель механізму.
Однак на етапі потоку електроенергії розподільної мережі, стикаючись із десятками тисяч або сотнями тисяч вузлів живлення, вузлів навантаження та традиційних
матричні алгоритми у великій розподільчій мережі безсилі.
Я вірю, що розпізнавання образів штучного інтелекту на рівні розподільної мережі стане можливим у майбутньому.
2. Накопичення, навчання та генерація неструктурованої інформації
Друга причина, чому AIGC зробила прорив, це накопичення інформації.З аналого-цифрового перетворення мови (мікрофон + PCM
вибірки) до аналого-цифрового перетворення зображень (CMOS+відображення колірного простору), люди накопичили голографічні дані в зорових і слухових
за останні кілька десятиліть надзвичайно дешевими способами.
Зокрема, масштабна популяризація фотоапаратів і смартфонів, накопичення неструктурованих даних в аудіовізуальному полі для людини.
за майже нульової вартості, а вибухове накопичення текстової інформації в Інтернеті є ключем до навчання AIGC – набори навчальних даних недорогі.
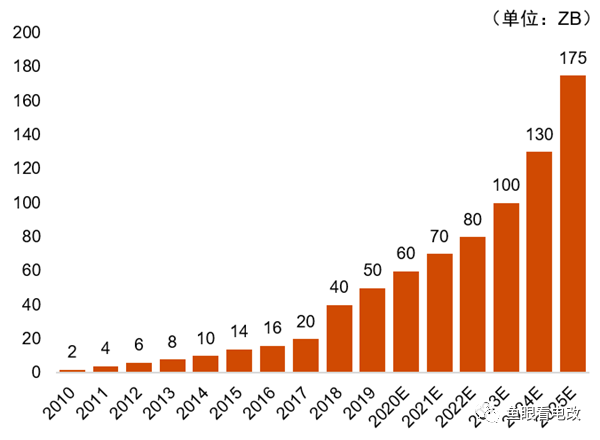
На малюнку вище показано тенденцію зростання глобальних даних, яка чітко демонструє експоненціальний тренд.
Це нелінійне зростання накопичення даних є основою для нелінійного зростання можливостей AIGC.
АЛЕ більшість цих даних є неструктурованими аудіовізуальними даними, які накопичуються без витрат.
У сфері електроенергетики цього не досягти.По-перше, більшість електроенергетичної промисловості є структурованими та напівструктурованими даними, такими як
напруга та струм, які є точковими наборами даних часових рядів і напівструктурованими.
Набори структурних даних мають бути зрозумілі комп’ютерам і вимагають «вирівнювання», наприклад, вирівнювання пристрою – дані про напругу, струм і потужність
комутатора потрібно узгодити з цим вузлом.
Більш складним є вирівнювання часу, яке вимагає вирівнювання напруги, струму, активної та реактивної потужності на основі шкали часу, щоб
можна провести подальшу ідентифікацію.Є також прямий і зворотний напрямки, які є просторовим вирівнюванням у чотирьох квадрантах.
На відміну від текстових даних, які не потребують вирівнювання, абзац просто передається на комп’ютер, який визначає можливі інформаційні асоціації
самостійно.
Для того, щоб узгодити це питання, як-от узгодження обладнання даних розподілу бізнесу, постійно потрібне узгодження, оскільки середовище та
розподільна мережа низької напруги щодня додає, видаляє та модифікує обладнання та лінії, а мережеві компанії витрачають величезні витрати на робочу силу.
Як і «анотація даних», комп’ютери не можуть цього зробити.
По-друге, вартість збору даних в енергетичному секторі висока, і замість мобільного телефону потрібні датчики, щоб розмовляти та фотографувати.»
Щоразу, коли напруга зменшується на один рівень (або залежність розподілу потужності зменшується на один рівень), необхідні інвестиції в датчик збільшуються
принаймні на один порядок величини.Щоб досягти зондування на стороні навантаження (капілярного кінця), це ще більше значні цифрові інвестиції».
При необхідності виявлення перехідного режиму електромережі необхідна високоточна високочастотна дискретизація, а вартість ще вище.
Через надзвичайно високу граничну вартість збору та узгодження даних енергомережа наразі не в змозі накопичувати достатню кількість нелінійних
зростання інформації про дані для навчання алгоритму для досягнення сингулярності ШІ.
Не кажучи вже про відкритість даних, для потужного AI-стартапу неможливо отримати ці дані.
Тому перед штучним інтелектом необхідно вирішити проблему наборів даних, інакше загальний код штучного інтелекту неможливо навчити створювати хороший ШІ.
3. Прорив у обчислювальній потужності
На додаток до алгоритмів і даних, прорив унікальності AIGC також є проривом в обчислювальній потужності.Традиційні процесори – ні
підходить для великомасштабних паралельних нейронних обчислень.Саме застосування графічних процесорів у 3D-іграх і фільмах робить масштабні паралельні
можливі обчислення з плаваючою точкою + потокове обчислення.Закон Мура додатково зменшує обчислювальні витрати на одиницю обчислювальної потужності.
ШІ електромережі, неминуча тенденція майбутнього
Завдяки інтеграції великої кількості розподілених фотоелектричних і розподілених систем зберігання енергії, а також вимог до застосування
віртуальних електростанцій з боку навантаження, об’єктивно необхідно проводити прогнозування джерела та навантаження для загальнодоступних розподільчих мереж і користувачів
системи розподільних (мікро) мереж, а також оптимізацію потоку електроенергії в режимі реального часу для систем розподільчих (мікро) мереж.
Обчислювальна складність сторони розподільної мережі фактично вища, ніж складність планування мережі передачі.Навіть для реклами
комплекс, можуть існувати десятки тисяч навантажувальних пристроїв і сотні комутаторів, а також попит на роботу мікромереж/розподільчих мереж на основі ШІ
виникне контроль.
Завдяки низькій вартості датчиків і широкому використанню силових електронних пристроїв, таких як твердотільні трансформатори, твердотільні перемикачі та інвертори (перетворювачі),
інноваційною тенденцією також стала інтеграція зондування, обчислення та керування на межі електромережі.
Тому за АІГК електромережі майбутнє.Однак те, що сьогодні потрібно, так це не відразу використовувати алгоритм ШІ, щоб заробляти гроші,
Натомість спершу вирішіть питання побудови інфраструктури даних, необхідні ШІ
На підйомі AIGC необхідно досить спокійно думати про рівень застосування та майбутнє потужного ШІ.
В даний час значення енергетичного штучного інтелекту не є значним: наприклад, фотоелектричний алгоритм з точністю прогнозування 90% розміщений на спотовому ринку.
з порогом торгового відхилення 5%, і відхилення алгоритму знищить усі торгові прибутки.
Дані — вода, а обчислювальна потужність алгоритму — канал.Як трапиться, так і буде.
Час публікації: 27 березня 2023 р